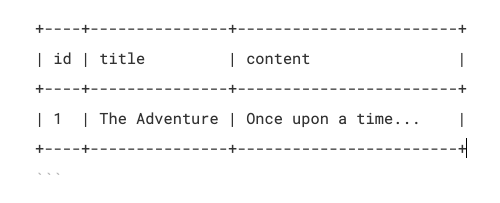
MySQL Node Issues

Sometimes we encounter problems with MySQL version and the mysql package for Node.js. To address this issue, we need to touch both Node.js projects and MySQL versions.
The Problem
Some of you are using the CodeOp projects/activities as guidance. Currently, those projects use the mysql package, which does not support caching_sha2_password, the default authentication plugin for MySQL 8.0 and above.
Additionally, MySQL 9 (the current default version) does not include the mysql_native_password security plugin. This mismatch is causing errors during migrations and database interactions.
The Solution
1. Migrate to the mysql2 Package
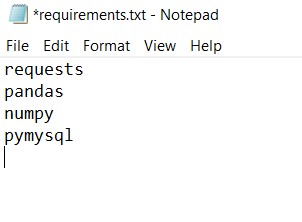
mysql2is fully compatible withcaching_sha2_passwordand offers better performance.- Only one person needs to make the necessary changes. The rest of the team can simply pull the updated code after it’s committed.
2. Keep MySQL Updated
- MySQL 9 uses
caching_sha2_passwordfor stronger encryption and better security. - Downgrading to older plugins like
mysql_native_passwordwould weaken security and is not recommended.
🍏 Steps to Update MySQL for Mac Users Using Homebrew
-
Check Your Current Version
Run the following in the terminal:
mysql --version -
If it’s not version 9+, stop the MySQL service:
brew services stop mysql -
Ensure Homebrew is up to date:
brew update -
Upgrade MySQL:
brew upgrade mysql -
Confirm the upgrade:
mysql --version -
Start the service:
brew services start mysql -
Test if MySQL is running:
mysql -u root -p
🤖 Steps for Windows Users
-
Uninstall MySQL 8 (if necessary)
-
Stop the MySQL Service:
Open the Services app (search “Services” in the Windows search bar).
Find MySQL, right-click, and select Stop. -
Uninstall MySQL:
Go to Control Panel > Programs > Programs and Features.
Locate MySQL Server, right-click, and choose Uninstall. -
Remove Residual Data (Optional):
Navigate to the MySQL data directory, usually located at:
C:\ProgramData\MySQL
-
-
Install MySQL 9
-
Download MySQL Installer:
Go to MySQL Community Downloads. -
Run the Installer:
Choose the Custom Install option.
Select MySQL Server 9.x (ensure it’s compatible with your architecture: x64 or x86).
Proceed with the installation. -
During Configuration:
Set the authentication plugin tocaching_sha2_password.
-
-
Start MySQL:
Use the MySQL Workbench or run the following command in the Command Prompt:
net start mysql -
Test if MySQL is running:
mysql -u root -p
⚠️ NEXT STEPS FOR ALL USERS
-
Open the MySQL command line:
Run the following command:
mysql -u root -p -
Update the authentication plugin for the root user:
Run the following query:ALTER USER 'root'@'localhost' IDENTIFIED WITH caching_sha2_password BY 'YOUR_PASSWORD';```
After updating the MySQL version, update the package and some code in your Node/Express project. This step needs to be performed by one person, and the others can pull the updated code once it's committed.
- On the server terminal of your project:
Remove the MySQL package:
npm uninstall mysql
Install the correct package:
npm install mysql2
- Replace MySQL import statements in your project files:
In your code, replace:
const mysql = require("mysql");
With:
const mysql = require("mysql2");
Make this change in the files:
helper.js database.js
5.Update the helper.js file: Remove the if/else if statements after the con.query block (approximately lines 36 to 55):
if (result.affectedRows === 0) {
results.error = "Action not complete";
console.log(err);
reject(err);
con.end();
return;
}
// Removed this line because it returns an array in an array when empty set
// results.data.push(result);
} else if (result[0].constructor.name == "RowDataPacket") {
// Push each row (RowDataPacket) to data
result.forEach(row => results.data.push(row));
} else if (result[0].constructor.name == "OkPacket") {
// Push the first item in result list to data
results.data.push(result[0]);
}
Before the con.end() statement, add the following line:
results.data = result;
With these updates, the rest of the code and the response structure will remain the same, so no further updates are required.